![]()

Our last junior job posting brought in over 300 applicants for one position. These unfortunate statistics put everyone’s odds of success less than 0.3% right out of the gate. It was honestly a bit of a heart-wrenching reminder about how the last few years of Alberta’s economy have impacted the jo...
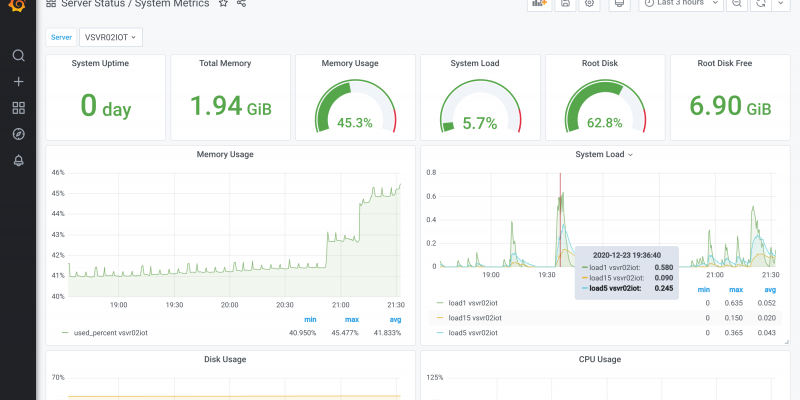
Dashboards are a great way to get at-a-glance diagnostics of a server's vital statistics. Consolidating this data from multiple servers in one place makes this server-sitting task even easier. A Linux server configured with Telegraf, InfluxDB and Grafana (a.k.a. a TIG stack) is an easy way...

I am very fortunate in that many of my hobbies and interests at home are in close alignment with my career in industrial automation. One of the foundational components of many of these interests, specifically around IoT and Data Science, is a home server for edge computing. I have maintained a Lin...
The COVID-19 pandemic has produced vast quantities of publicly available data that holds a prominent global interest. While the integrity and accuracy of the data has been scrutinized and questioned from nation to nation, the data still provides a great jumping point to explore some fundamental dat...
As nations and regions plan on restarting their economies and relaxing social distancing restrictions, there have been concerns raised that the data does not support the curve-flattening optimism used to rationalize the economic relaunching. The data for Canada and Alberta hold a selfish personal...

This post was originally published on www.tetranex.com, April 2017
One of the greatest examples of how leadership and innovation can propel an organization to achieve incredible goals played out in Canadian history 100 years ago this month. On April 9th – 12th, 1917, the Canadian Expeditionary...
Welcome to the virtual home of Phaedrus Technologies where we explore the likes of:
- Industrial Automation
- IoT
- Data Science
- Linux & Open Source
For commercial applications see:
 |
Tetranex Solutions |
|---|